Appendix
For the manuscript titled “Self-orthogonalizing attractor neural networks emerging from the free energy principle” by Tamas Spisak and Karl Friston¶
Library imports for inline code.
import numpy as np
import seaborn as sns
from matplotlib import pyplot as plt
import scipy.integrate as integrate
sns.set(style="white")Appendix 1¶
Continuous Bernoulli distribution
Below we provide a Python implementation of the continuous Bernoulli distributions: , parametrized by the log odds L and adjusted to the [-1,1] interval.
def CB(x, b, logodds=True):
if not logodds:
b=np.log(b/(1-b))
if np.isclose(b, 0):
return np.ones_like(x)/2
else:
return b * np.exp(b*x) / (2*np.sinh(b))
# Plot some examples
delta = 100
sigma = np.linspace(-1, 1, delta)
for b in np.linspace(-2, 2, 5):
p_sigma = CB(sigma, b)
sns.lineplot(x=sigma, y=p_sigma, label=b)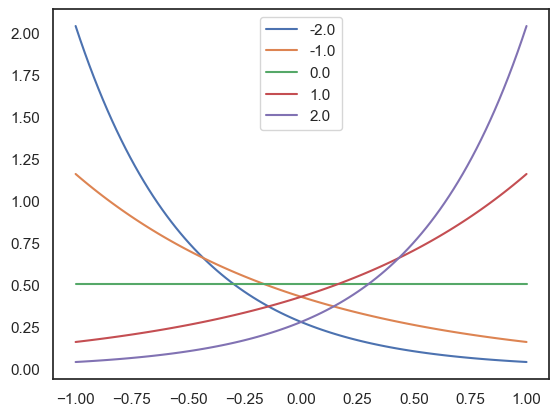
Appendix 2¶
Continuous Bernoulli distribution full derivation
Derivation of the exponential form of the continuous Bernoulli distribution, parametrized by the log odds L and adjusted to the [-1,1] interval.
Appendix 3¶
Visualization of the likelihood function with various parameters, in python.
delta = 100
s_i = np.linspace(-1, 1, delta)
fig, axes = plt.subplots(1, 3, figsize=(12, 3), sharey=True)
for idx, mu in enumerate([0.1, 0.5, 1]):
for w_i in np.linspace(-2, 2, 5):
p_mu = CB(s_i, w_i*mu)
sns.lineplot(x=s_i, y=p_mu, ax=axes[idx], label=w_i).set(title=f"$\\mu={mu}$")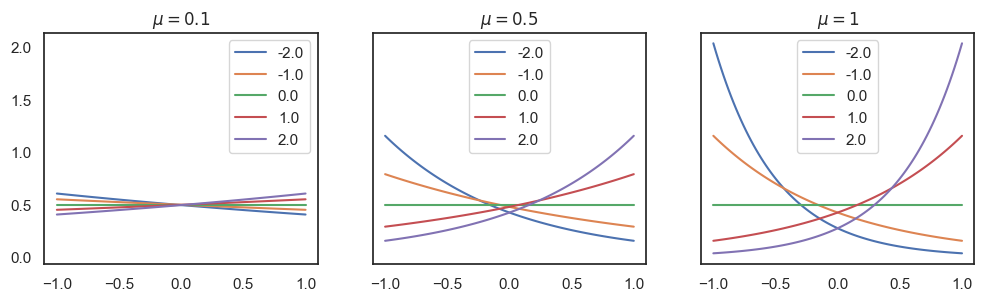
bs = np.linspace(-10, 10, 100)
plt.figure(figsize=(4, 1))
sns.lineplot(x=bs, y=1/np.tanh(bs) - 1/bs) # coth(b) - 1/b == 1/2 sech^2(b)
plt.show()
Appendix 5¶
Conservative dynamics
Let denote the system’s states (internal, blanket, and external states).
The drift can be decomposed into a gradient part (from a potential U) and a solenoidal part R:
where is antisymmetric in state‐space.
The probability density over states evolves according to the Fokker–Planck equation:
To determine the stationary distribution , we set . The Fokker-Planck equation then implies that the net probability current (assuming isotropic diffusion ) must be divergence-free: .
If we propose (where is a normalization constant), then the diffusive current becomes .
Substituting this into , we get:
.
Thus, is the stationary distribution if and only if the solenoidal component of the probability current, , is itself divergence-free: .
It is a key result from the study of non-equilibrium systems under the Free Energy Principle, particularly those possessing a Markov blanket and involving conservative particles, that this condition holds (see Friston et al., 2023; but also related: Ao (2004); Xing (2010)). The conditional independence structure imposed by the Markov blanket, along with other FEP-specific assumptions (like conservative particles), constrains the system’s dynamics such that solenoidal forces do not alter the Boltzmann form of the stationary distribution. Instead, they drive persistent, divergence-free probability currents along iso-potential surfaces.
In steady state , only the gradient term influences . The stationary (nonequilibrium) distribution is
,
determined solely by the symmetric (potential) part −∇U. The antisymmetric does not reweight ; it just circulates probability around isocontours of .
In most NESS systems, antisymmetric flows do alter the stationary measure. Under particular‐partition (Markov‐blanket) constraints, however, the internal–external factorization ensures that solenoidal (antisymmetric) flows remain divergence‐free, leaving the Boltzmann‐like steady distribution intact. This is why, in these Markov‐blanketed systems, one can have persistent solenoidal currents (nonequilibrium flows) yet preserve a stationary distribution that depends only on the symmetric part of the couplings.
Appendix 6¶
Detailed inference derivation: accuracy–complexity decomposition and
The main text derives the inference rule (eq. (15)) via a compact local VFE argument. Here we provide the equivalent — but more detailed — derivation via the accuracy–complexity decomposition of VFE, confirming the same result.
1. Subsitute our parametrization into F
Let’s start with substituting our parametrization into eq. .
1a. Accuracy term
From the RBM marginalization (eq. ):
Here, becomes constant, since is fixed. So we get:
Taking expectation of under :
Where is the expected value of the , a sigmoid function of the bias (#supplementary-information-4)).
1b. Complexity term
The complexity term in eq. is simply the KL-divergence term between two distributions. For distributions:
• KL divergence definition:
• Expand log terms:
• Subtract log terms:
• Take expectation under q(x):
• Compute expectation :
• Evaluate at bounds:
• Simplify using hyperbolic identities:
• Final substitution for the complexity term:
1c. Combining the two terms
Combining the two terms, we get the following expression for the free energy:
where C denotes all constants in the equation that are independent of .
2. Free Energy partial derivative calculation
• First, we differentiate the log terms:
• Then, the KL core term:
• The linear terms:
• The constants vanish.
• Now, combining all terms:
• Substituting :
• Cancel terms:
Gives us the final derivative:
Where .
Setting the derivative to zero and solving for , we get:
Now we remember that the expected value of the is the Langevin function of its bias -, (). For simplicity, we will denote it as . Now we can write:
Q.E.D.
Appendix 7¶
Basin geometry and adversarial robustness
We provide a geometric analysis of how attractor orthogonality and the precision parameter jointly affect adversarial robustness in the proposed framework.
Setup. Consider a network with nodes, inverse temperature , and stored attractors with . Under the projector weight matrix (zero diagonal), which the learning rule approximates, the energy at a stored attractor satisfies .
Adversarial budget and representational redundancy. An adversarial perturbation applied to the bias vector shifts the energy difference between two attractors and by . The most efficient attack aligns with the difference vector, yielding a minimum perturbation norm . For orthogonal attractors (): . For attractors with normalized overlap : . Since , orthogonal attractors () maximize the adversarial budget. Self-orthogonalization thus reduces representational redundancy (overlap between attractor states) while increasing robustness to targeted perturbations.
Structural redundancy. Although representational redundancy is minimized, structural redundancy is fully preserved: each attractor is encoded across all synaptic weights, with each weight contributing to the basin depth. Corrupting or removing a bounded fraction of weights therefore has a limited effect on the energy landscape, regardless of attractor orthogonality.
Prior precision as a defense. Under finite temperature, the posterior is . The effective basin depth scales as , while the perturbation contributes . The ratio of basin depth to perturbation magnitude grows with : high precision makes prior-encoded attractors robust to sensory-level attacks. The converse also holds: low down-weights the prior, limiting the influence of poisoned attractors on the posterior.
Stochastic averaging. Beyond the geometric analysis, stochastic MCMC inference provides an additional defense layer. The time-averaged network response converges to the posterior mean , with variance decreasing as where is the effective number of independent samples. This averaging smooths out the effect of perturbations that shift individual samples but do not move the posterior mode across a basin boundary.
Implicit regularization against data poisoning. During learning, the anti-Hebbian term in the learning rule subtracts the network’s current prediction from the observed correlation. For a corrupted training pattern, the prediction — dominated by the clean attractor subspace — absorbs most of the pattern’s variance, leaving only a small residual update. For a poisoning fraction , the cumulative effect of poisoned updates remains bounded relative to the clean learning signal, analogous to the outlier-robustness of Bayesian posteriors under informative priors.
Appendix 8¶
Detailed comparison with classical models
We compare the proposed FEP-based attractor network (FEP-ANN) with the canonical formulations of classical Hopfield networks, Boltzmann machines, projector (pseudo-inverse) networks, and hierarchical predictive coding. Each of these model families encompasses many variants; the comparison targets the canonical baseline in each case.
Learning rule and computational complexity
Boltzmann machines (contrastive divergence). The exact gradient of the Boltzmann log-likelihood with respect to weights is
where requires sampling from the model’s equilibrium distribution — computationally intractable for large networks. Contrastive divergence (CD-) approximates by running steps of Gibbs sampling from the data-initialized state. Each Gibbs sweep visits all nodes, and computing the input to each node requires multiplications, yielding a per-step cost of per Gibbs sweep and per weight update.
FEP-ANN. The learning rule for node uses the network’s instantaneous predicted state — a single forward pass through the current weights — rather than a sample average over model-generated states. Computing for all nodes requires one matrix-vector product at ; the outer-product updates for all weights then cost . The total per-step learning cost is therefore — a factor of cheaper than CD-. The free-running phase is eliminated entirely.
Solenoidal flows and mixing times In a symmetric Boltzmann machine, inference proceeds via reversible Gibbs sampling; reversibility implies that probability mass can only move between attractor basins by climbing over energy barriers, leading to mixing times that scale exponentially with barrier height.
In the FEP-ANN with asymmetric couplings , the dynamics decompose into a gradient (dissipative) component driven by and a solenoidal (conservative) component driven by . The solenoidal term does not alter the stationary distribution but induces persistent probability currents along iso-energy contours. These non-reversible currents transport probability mass between attractor basins without climbing energy barriers — they traverse along the iso-energy surface instead, accelerating mixing. The resulting dynamics are formally analogous to continuous normalizing flows and Markovian flow matching.Orthogonalization and memory capacity Classical Hopfield networks with Hebbian (outer-product) weights store patterns; cross-talk limits capacity to . Projector (pseudo-inverse) networks achieve optimal capacity with error-free retrieval but require batch access and computation. In the FEP-ANN, the Hebbian/anti-Hebbian learning rule incrementally approximates the projector matrix through online learning: the Hebbian term accumulates pattern correlations while the anti-Hebbian term subtracts the model’s current prediction, progressively decorrelating the stored representations. Memory capacity thus approaches the projector limit without batch computation or matrix inversion.
Relationship to hierarchical predictive coding Both the FEP-ANN and hierarchical predictive coding (PC) networks minimize variational free energy via local, prediction-error-driven updates. The structural difference is topology: PC operates on a bidirectional hierarchy with directed inter-layer connections (feedforward predictions, feedback prediction errors), while the FEP-ANN uses a fully recurrent, single-layer topology with arbitrary lateral couplings. Within the deep particular partition formalism, both are instances of the same FEP-based inference architecture applied to different coupling topologies. Exploring the formal equivalences between these topologies is a promising direction for future work.
Table 1:Comparison of the FEP-ANN with canonical formulations of classical models.
| Feature | Hopfield | Boltzmann machine | Projector network | Predictive coding | FEP-ANN (ours) |
|---|---|---|---|---|---|
| Derivation | Energy-based | Statistical mechanics | Optimal storage | Hierarchical Bayesian | First principles (FEP) |
| State space | Binary | Binary | Binary | Continuous (Gaussian) | Continuous (CB) |
| Activation | Sign | Logistic sigmoid | Sign | Linear / nonlinear | Langevin (emergent) |
| Learning | Hebbian (batch) | Contrastive divergence | Pseudo-inverse (batch) | Prediction-error min. | Hebbian/anti-Hebbian (online) |
| Learning phases | One-shot | Clamped + free | One-shot | Layerwise | Single phase |
| Coupling | Symmetric | Symmetric | Symmetric | Directed (hierarchy) | Symmetric or asymmetric |
| Sequence dynamics | No | No | No | Temporal hierarchy | NESS solenoidal flow |
| Orthogonalization | No | No | By construction | No | Emergent (VFE) |
| Memory capacity | (optimal) | N/A (generative) | Approaches | ||
| Inference | Deterministic | Gibbs MCMC | Deterministic | Message passing | MCMC + solenoidal flow |
| Precision control | None | Temperature (fixed) | None | Precision-weighting | (Bayesian) |
| Continual learning | Catastrophic forgetting | Catastrophic forgetting | Catastrophic forgetting | Possible (with replay) | Built-in (spontaneous replay) |
| Learning complexity | one-shot | per step | one-shot | per layer per step | per step |
| FEP / active inference | No formal link | Variational (post hoc) | No formal link | Compatible | Derived from FEP |
Appendix 9¶
Scaling benchmarks
We report runtime and memory capacity benchmarks for the JAX implementation across network sizes from to and pattern counts from to .
Training and inference wall-clock time as a function of network size , confirming the expected per-step scaling. Panel to be finalized with benchmark data from 07-simulation-scaling-jax.ipynb.
Table: Runtime benchmarks (JAX implementation, 10 updates)
| (nodes) | Training time (s) | Throughput (steps/s) |
|---|---|---|
| 100 | 0.004 | 2455 |
| 1 000 | 0.007 | 1390 |
| 5 000 | 0.26 | 39.1 |
| 10 000 | 0.39 | 25.5 |
| 20 000 | 1.49 | 6.69 |
| 50 000 | 59.8 | 0.167 |
- Friston, K., Da Costa, L., Sakthivadivel, D. A. R., Heins, C., Pavliotis, G. A., Ramstead, M., & Parr, T. (2023). Path integrals, particular kinds, and strange things. Physics of Life Reviews, 47, 35–62. 10.1016/j.plrev.2023.08.016
- Ao, P. (2004). Potential in stochastic differential equations: novel construction. Journal of Physics A: Mathematical and General, 37(3), L25–L30. 10.1088/0305-4470/37/3/l01
- Xing, J. (2010). Mapping between dissipative and Hamiltonian systems. Journal of Physics A: Mathematical and Theoretical, 43(37), 375003. 10.1088/1751-8113/43/37/375003